
When systems go down, the first questions are almost always technical. How long until the server is back? Can we restore the backups? What is our recovery time? These questions matter, but they miss a bigger truth. The damage of an outage rarely stays inside the IT department. It spreads into sales, operations, customer relationships, and the decisions your leaders make under pressure.
The numbers back this up. The ITIC 2024-2025 Hourly Cost of Downtime Survey found that more than 90% of mid-size and large organizations say a single hour of downtime costs them over $300,000, and 41% put the figure between $1 million and $5 million per hour. Those losses do not come out of the IT budget. They come out of revenue, productivity, and trust.
So the real question is not how quickly your technology comes back. It is how well your business keeps running while it is down.

Why Downtime Is a Business Event, Not an IT Problem
Many recovery plans get built around technology. Teams track backup success rates, recovery tools, system availability, and infrastructure redundancy. These details matter, but they do not answer the question that actually decides the downtime impact: what happens to the business when a system becomes unavailable?
Picture two companies hit by the same outage. One restores its servers in two hours, the other in four. The faster one looks better, until you learn its outage struck during its busiest sales day. The quicker technical recovery caused the bigger business loss.
Uptime metrics describe machines. Business impact describes people, money, and commitments. Measure only the machines, and you miss the part that drives your real business downtime cost: your customers and your bottom line.

The Real Business Downtime Cost Goes Past Server Repair
The direct expense of restoring a system is usually the smallest part of the bill. The larger business downtime cost shows up in places that never appear on an IT invoice.
1. Revenue takes an immediate hit.
When systems stall, you cannot process orders, complete transactions, or send invoices on time. Sales slip away, and some customers do not come back to try again.
2. Operations slow or stop.
Employees sit idle waiting for tools, workflows break, and a production line or service team can grind to a halt. If you rely on suppliers or partners, their delays pile on top of yours.
3. Customers feel the disruption.
Missed deadlines, failed logins, and silent support lines chip away at the experience you promised, and trust is slow to build but quick to lose.
4. Regulatory and contractual exposure grows.
Some industries require reporting inside set windows, and a long outage can make you miss those deadlines or break service agreements, which adds penalties on top of the disruption.
5. Reputation suffers last but lingers longest.
Word of an outage spreads, competitors step in, and the hardest cost to measure is the customer who quietly shops elsewhere.
Most of these business interruption costs are indirect, and together they often dwarf the technical fix. A true business downtime cost is a business figure, not a line item in the server budget.

RTO and RPO Are Business Decisions, Not Technical Ones
Leaders often hand Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs) to the IT team and treat them as settings. The RTO vs. RPO discussion belongs in the boardroom because both metrics describe how much pain the business can absorb.
Your Recovery Time Objective answers a business question: how long can a process stay down before the damage becomes serious?
Your Recovery Point Objective answers another: how much recent data can you afford to lose before operations take a real hit?
These answers change by function. A payroll system that runs every two weeks may tolerate a longer outage than a customer portal that drives daily sales. An ERP platform, a manufacturing line, and a patient management system each carry very different stakes. Set recovery targets around the value each process creates, not the technology behind it. That keeps your disaster recovery planning tied to what the business needs.

Downtime Doesn't Always Start With a Technology Failure
It is tempting to picture downtime as a crashed server, but the causes are much wider. A ransomware attack can lock your files. A cloud provider outage can take your tools offline. A single human error, like a bad configuration or a deleted record, can stall a whole workflow. Identity compromise, network failures, and trouble at a third-party vendor all lead to the same place.
The trigger changes, but the business effect looks the same: work stops, customers wait, and revenue pauses. This is why strong downtime risk management does not fixate on one type of failure. It prepares for the shared outcome that every cause produces.
Cybersecurity and Business Continuity Belong in the Same Conversation
Many organizations still keep these teams in separate rooms. Security handles threats, IT handles systems, a disaster recovery group handles backups, and a continuity team handles planning. Each works hard inside its own lane.
Real disruptions ignore those lanes. A security failure hurts availability, lost availability stalls operations, stalled operations cut into revenue, and slow recovery threatens the whole business. The chain runs straight through every team, which is why business continuity cybersecurity works best as one connected effort instead of separate projects.
When security, infrastructure, recovery, and continuity planning share the same view, decisions get faster and cleaner. We explored this same problem in our blog on why integrated design beats layered security every time, where the spaces between disconnected tools and teams create the openings that cause the most damage.

Moving Past Recovery Planning Toward Operational Resilience
Getting technology back online is only half the job. The stronger goal is operational resilience: your business keeps serving customers even while parts of it are under stress.
Plans on paper and performance in a real event are two different things. The Veeam Data Trust and Resilience Report 2026, based on more than 900 senior IT, security, and risk leaders, found that 90% believed they could recover after a ransomware attack, yet only 28% of victims fully recovered their data. Confidence is not the same as capability.
Closing that gap takes more than backups. The most resilient organizations:
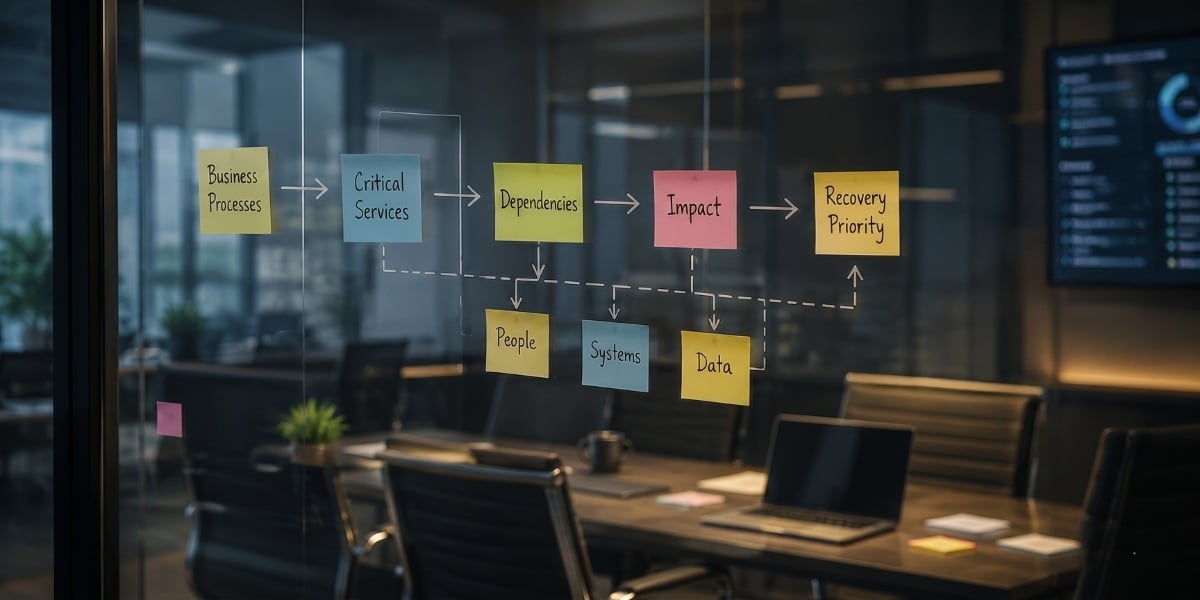
- Map their business processes and what each one depends on.
- Trace which systems support the work that creates the most value.
- Rank recovery by business priority, not by which system is easiest to bring back.
- Test their recovery instead of assuming it works.
- Run tabletop exercises so teams practice decisions before a crisis.
- Fold incident response into the plan so investigation and recovery move together.
- Validate the plan often, because environments change.
A solid business continuity strategy treats recovery as an ongoing capability, not a document in a drawer. Cyber recovery planning works the same way, since restoring a business safely after an attack asks security, infrastructure, and operations to act as one.
Start With the Business, Then Work Back to the Technology
The companies that handle disruption well share one habit. They plan recovery around business priorities first and technology second, then connect their security, infrastructure, and recovery work so it moves as one system instead of separate parts. This is the approach RedHelm builds for clients, pairing cybersecurity, managed IT, and cloud environments designed to keep the business running when something goes wrong.
If you are not sure how long your business could keep operating during a major outage, that uncertainty is where to start. Book a conversation with the RedHelm team to map your priorities and find the gaps before they turn into real losses.
